
Large Language Models showed that they could actually perform extremely well on tasks with input data that they did not see during training. This is called zero-shot learning, and it is a very interesting phenomenon. Before the world met GPT-3, the only way to make the model learn a new task was to fine-tune the model on the new task with custom dataset. However, GPT-3 showed that it could perform well on a new task without any fine-tuning.
In 2023, it is still mistery how GPT-3 can perform well on a new task without any fine-tuning. People are just guessing that it is because of the large size of the model with the large amount of dataset, but nothing is certain.
Since the LLMs’ zero-shot learning outperforms the fine-tuning the small language models, people are now trying to make the LLMs handle new tasks with well-designed prompts. This is called prompt engineering, and it is a very interesting topic.
One of the simplest prompting methods is just giving instructions (sometimes called instruction prompting). For example, if you want to make the LLM to answer the arithmetic question, you can just give the instruction like this:
1
Make sure your answer is exactly correct. What is 965*590? Make sure your answer is exactly correct:
When the LLM sees this prompt, it will generate the answer like this:
1
965*590=982302
You could see that the format of the output is correct, but the answer is wrong. This is basically because that the GPT-based LLMs are simply doing “next word prediction” task for answering. It just embeds the given instruction input, compute complex matrix multiplications with the input embedding vectors and the weights of the model. Then, it generates the output token by token, where each token is the most probable token given the previous tokens.
As the GPT-3 trained with both supervised learning and “in-context learning” (which is basically self-supervised learning with well-formatted instruction prompts), it can nearly “understand” the context of the instruction prompts. To test this, many researchers tried to find the most effective prompts for each task. While doing this, they find new technique called “Chain of Thought” (COT) prompting.
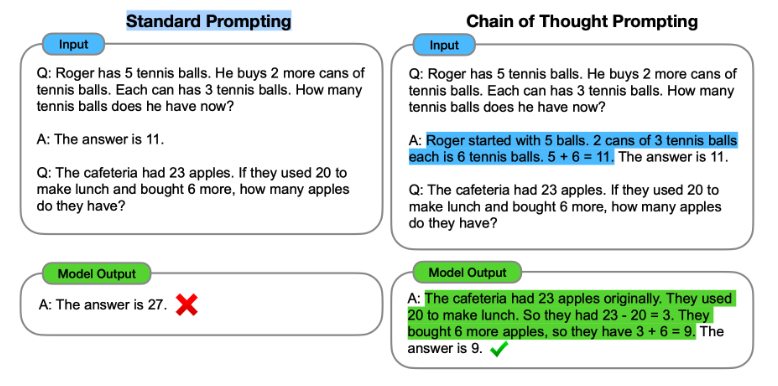
Chain of Thought Prompting
Chain of Thought (CoT) prompting is a recently developed prompting method, which encourages the LLM to explain its reasoning.
The main idea of CoT is that by showing the LLM some few shot exemplars where the reasoning process is explained in the exemplars, the LLM will also show the reasoning process when answering the prompt. This explanation of reasoning often leads to more accurate results.
Let’s go back to the example instruction prompt for arithmetic question. We wanted the LLM to answer the question “965*590=?”, where the LLM answered “982302”, which is wrong. However, if we reinforce the prompt with the exemplar of the correct answer, the LLM will answer the question correctly.
1
2
3
4
5
6
7
Q: Make sure your answer is exactly correct. What is 965*590? Make sure your answer is exactly correct:
A: 965*590 = 965 * 600 - 965 * 10 = 579000 - 9650 = 569350
Q: Make sure your answer is exactly correct. What is 965*580? Make sure your answer is exactly correct:
A:
If you give this prompt to the LLM, it will answer the question correctly.
1
965 * 580 = 965 * 600 - 965 * 20 = 579000 - 19300 = 559700
This is because that the LLM learned the reasoning process from the exemplar. Researchers think this process is something similar with the human learning process that chaning the thoughts, so they named this prompting method as CoT(“Chain of Thought”) prompting.
Later this is developed to Zero-shot Chain of Thought prompting, which abstracts the reasoning process from the exemplar and make the LLM to learn the reasoning process from the exemplar.
So, is it worth to do prompt engineering?
The prompt engineering relies on the LLM’s zero-shot learning ability. It might be possible to make better result if you have enough amount of data with good base model (i.e. LLaMa, etc). However, if you do not have enough amount of data for fine-tuning, then the prompt engineering is definitely worth to go.
Using prompt engineering means that you are simply consider the LLM as a magical black-box, and you are just trying to find the best way to communicate with the black-box. Unlike ML/DL, which automatically finds the better way by learning from data, prompt engineering is more like a human engineering. The LLM will not teach you the best prompt automatically, so you have to find the best prompt by yourself. Also, unlike ML/DL, there is no way to measure the performance of the prompt engineering, since we do not have any metric to measure the performance of the prompt engineering. This will be a hard time if you are not interested in playing various prompts with LLMs until you find the best prompt.
Furthermore, if you find a magical prompt that works well on a specific LLM model with specific task, this will gonna left in the dust in the future, since the base LLM model will be updated, which means that overfitted prompts will not work anymore.
Clearly, prompt engineering could make your life better. There is no doubt that well-designed prompt will make the LLM to perform better on the task. It definitely could outperform the existing fine-tuning methods. However, there is no guarantee that it will work well in the future. So, you need to invest your time and effort to find the best prompt for your task with plan B (or maybe plan C as well) to prepare for the future that your overfitted-prompt will not work anymore.
Then, do we need to train out own model?
If there is a possibility that the result of prompt engineering will be left in the dust in the future, then why do we need to train our own model?
My answer will be “Not necessarily”.
If you have enough amount of data with good base model and powerful infrastructure that could handle the training process of LLM, then it is definitely worth to train your own model.
Also, the prompt engineering is not always working well. The LLM will still make mistakes even with the best prompts. You should use additional methods to overcome this issue, such as using fine-tuned open-sourced LLM or ensembling fine-tuned small language models.
No one knows the future, so you should prepare for the future with various methods. The one who is well-prepared might win the future.