
You only look once (YOLO) is an object detection system targeted for real-time processing.
Table of Contents
How YOLO works
YOLO divides the input image into an S×S grid. Each grid cell predicts only one object. For example, the yellow grid cell below tries to predict the “person” object whose center (the blue dot) falls inside the grid cell. Each grid cell predicts a fixed number of boundary boxes.
However, the one-object rule limits how close detected objects can be. For that, YOLO does have some limitations on how close objects can be.
For each grid cell,
1
2
3
it predicts B boundary boxes and each box has one box confidence score,
it detects one object only regardless of the number of boxes B,
it predicts C conditional class probabilities (one per class for the likeliness of the object class).
Let’s get into more details. Each boundary box contains 5 elements: (x, y, w, h) and a box confidence score. The confidence score reflects how likely the box contains an object (objectness) and how accurate is the boundary box. We normalize the bounding box width w and height h by the image width and height. x and y are offsets to the corresponding cell. Hence, x, y, w and h are all between 0 and 1. Each cell has 20 conditional class probabilities. The conditional class probability is the probability that the detected object belongs to a particular class (one probability per category for each cell). So, YOLO’s prediction has a shape of (S, S, B×5 + C) = (7, 7, 2×5 + 20) = (7, 7, 30).
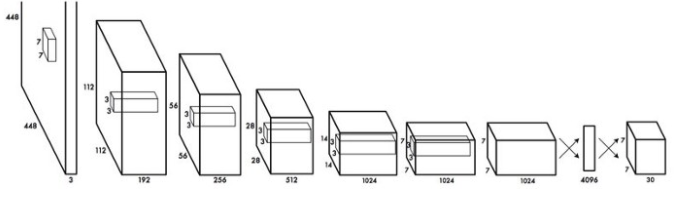
The major concept of YOLO is to build a CNN network to predict a (7, 7, 30) tensor. It uses a CNN network to reduce the spatial dimension to 7×7 with 1024 output channels at each location. YOLO performs a linear regression using two fully connected layers to make 7×7×2 boundary box predictions. To make a final prediction, we keep those with high box confidence scores (greater than 0.25) as our final predictions.
Confidence score
The class confidence score measures the confidence on both the classification and the localization (where an object is located).
The class confidence score for each prediction box is computed as:
1
class_confidenc_score = box_confidence_score * conditional_class_probability
and
1
2
box_confidence_score = P_r(object) * IoU
conditional_class_probability = P_r(class_i | object)
where
1
2
3
4
P_r(object) is the probability that the box contains an object
IoU is an IoU(intersection of union) between the predicted box and the ground truth
P_r(class_i | object) is the probability the object belongs to class_i given an object is presence
P_r(class_i) is the probability the object belongs to class_i
By combining the equations above, we could derive the following equation:
1
2
3
class_confidenc_score
= box_confidence_score * conditional_class_probability
= P_r(object) * IoU * P_r(class_i | object)
Loss Function
The YOLO model calculates the Loss by adding all classification loss, localization loss, and confidence loss. For more details, please read this paper [1].
Benefits of YOLO
1
2
3
4
5
- Fast. Good for real-time processing.
- Predictions (object locations and classes) are made from one single network. Can be trained end-to-end to improve accuracy.
- YOLO is more generalized. It outperforms other methods when generalizing from natural images to other domains like artwork.
- Region proposal methods limit the classifier to the specific region. YOLO accesses to the whole image in predicting boundaries. With the additional context, YOLO demonstrates fewer false positives in background areas.
- YOLO detects one object per grid cell. It enforces spatial diversity in making predictions.
Credits of this section
I declare that most of the contents in this section (How YOLO works) come from this article [2]. Credits to the author of the article.
YOLOv2
Comparing with region based detectors, YOLO has higher localization errors and the recall (measure how good to locate all objects) is lower. YOLOv2 is the second version of the YOLO with the objective of improving the accuracy significantly while making it faster.
Accuracy improvements
Batch Normalization
Add batch normalization in convolution layers. This removes the need for dropouts and pushes mAP up 2%.
High-resolution classifier
The YOLO training composes of 2 phases. First, we train a classifier network like VGG16. Then we replace the fully connected layers with a convolution layer and retrain it end-to-end for the object detection. YOLO trains the classifier with 224 × 224 pictures followed by 448 × 448 pictures for the object detection. YOLOv2 starts with 224 × 224 pictures for the classifier training but then retune the classifier again with 448 × 448 pictures using much fewer epochs. This makes the detector training easier and moves mAP up by 4%.
Convolutional with Anchor Boxes
As indicated in the YOLO paper [1], the early training is susceptible to unstable gradients. Initially, YOLO makes arbitrary guesses on the boundary boxes. These guesses may work well for some objects but badly for others resulting in steep gradient changes. In early training, predictions are fighting with each other on what shapes to specialize on.
In the real-life domain, the boundary boxes are not arbitrary. Cars have very similar shapes and pedestrians have an approximate aspect ratio of 0.41. Since we only need one guess to be right, the initial training will be more stable if we start with diverse guesses that are common for real-life objects.
For example, we can create 5 anchor boxes with the following shapes.
Instead of predicting 5 arbitrary boundary boxes, we predict offsets to each of the anchor boxes above. If we constrain the offset values, we can maintain the diversity of the predictions and have each prediction focuses on a specific shape. So the initial training will be more stable.
In the paper [2], anchors are also called priors.
Here are the changes we make to the network:
1
2
3
4
5
6
7
8
9
- Remove the fully connected layers responsible for predicting the boundary box.
- We move the class prediction from the cell level to the boundary box level. Now, each prediction includes 4 parameters for the boundary box, 1 box confidence score (objectness) and 20 class probabilities. i.e. 5 boundary boxes with 25 parameters: 125 parameters per grid cell. Same as YOLO, the objectness prediction still predicts the IOU of the ground truth and the proposed box.
- To generate predictions with a shape of 7 × 7 × 125, we replace the last convolution layer with three 3 × 3 convolutional layers each outputting 1024 output channels. Then we apply a final 1 × 1 convolutional layer to convert the 7 × 7 × 1024 output into 7 × 7 × 125.
- Change the input image size from 448 × 448 to 416 × 416. This creates an odd number spatial dimension (7×7 v.s. 8×8 grid cell). The center of a picture is often occupied by a large object. With an odd number grid cell, it is more certain on where the object belongs.
- Remove one pooling layer to make the spatial output of the network to 13×13 (instead of 7×7).
Anchor boxes decrease mAP slightly from 69.5 to 69.2 but the recall improves from 81% to 88%. i.e. even the accuracy is slightly decreased but it increases the chances of detecting all the ground truth objects.
Dimension Clusters
In many problem domains, the boundary boxes have strong patterns. For example, in the autonomous driving, the 2 most common boundary boxes will be cars and pedestrians at different distances. To identify the top-K boundary boxes that have the best coverage for the training data, we run K-means clustering on the training data to locate the centroids of the top-K clusters.
Since we are dealing with boundary boxes rather than points, we cannot use the regular spatial distance to measure datapoint distances.
No surprise, we use IoU.
Direct location prediction
We make predictions on the offsets to the anchors. Nevertheless, if it is unconstrained, our guesses will be randomized again. YOLO predicts 5 parameters (tx, ty, tw, th, and to) and applies the sigma function to constraint its possible offset range.
According to J. Redmon et. al. [3], with the use of k-means clustering (dimension clusters) and the improvement mentioned in this section, mAP increases 5%.
Fine-Grained Features
Convolution layers decrease the spatial dimension gradually. As the corresponding resolution decreases, it is harder to detect small objects. Other object detectors like SSD locate objects from different layers of feature maps. So each layer specializes at a different scale. YOLO adopts a different approach called passthrough. It reshapes the 26 × 26 × 512 layer to 13 × 13 × 2048. Then it concatenates with the original 13 × 13 ×1024 output layer. Now we apply convolution filters on the new 13 × 13 × 3072 layer to make predictions.
Multi-Scale Training
After removing the fully connected layers, YOLO can take images of different sizes. If the width and height are doubled, we are just making 4x output grid cells and therefore 4x predictions. Since the YOLO network downsamples the input by 32, we just need to make sure the width and height is a multiple of 32. During training, YOLO takes images of size 320×320, 352×352, … and 608×608 (with a step of 32). For every 10 batches, YOLOv2 randomly selects another image size to train the model. This acts as data augmentation and forces the network to predict well for different input image dimension and scale. In additional, we can use lower resolution images for object detection at the cost of accuracy. This can be a good tradeoff for speed on low GPU power devices. At 288 × 288 YOLO runs at more than 90 FPS with mAP almost as good as Fast R-CNN. At high-resolution YOLO achieves 78.6 mAP on VOC 2007.
Accuracy comparison with YOLO
Here is the accuracy improvements after applying the techniques discussed so far:

Speed Improvement
GoogLeNet
VGG16 requires 30.69 billion floating point operations for a single pass over a 224 × 224 image versus 8.52 billion operations for a customized GoogLeNet. We can replace the VGG16 with the customized GoogLeNet. However, YOLO pays a price on the top-5 accuracy for ImageNet: accuracy drops from 90.0% to 88.0%.
DarkNet
We can further simplify the backbone CNN used. Darknet requires 5.58 billion operations only. With DarkNet, YOLO achieves 72.9% top-1 accuracy and 91.2% top-5 accuracy on ImageNet. Darknet uses mostly 3 × 3 filters to extract features and 1 × 1 filters to reduce output channels. It also uses global average pooling to make predictions.
Here is the detail network description:
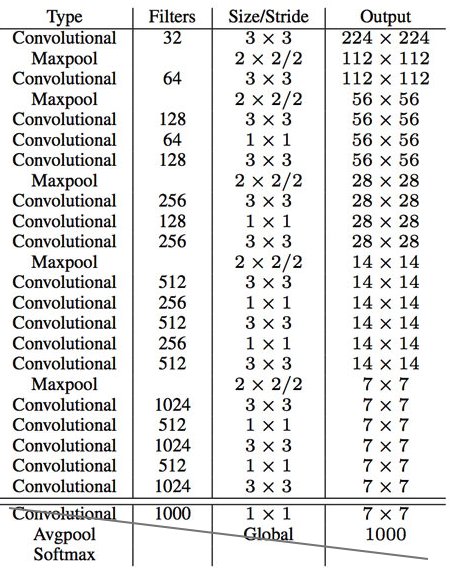
We replace the last convolution layer (the cross-out section) with three 3 × 3 convolutional layers each outputting 1024 output channels. Then we apply a final 1 × 1 convolutional layer to convert the 7 × 7 × 1024 output into 7 × 7 × 125. (5 boundary boxes each with 4 parameters for the box, 1 objectness score and 20 conditional class probabilities)
Training
YOLO is trained with the ImageNet 1000 class classification dataset in 160 epochs: using stochastic gradient descent with a starting learning rate of 0.1, polynomial rate decay with a power of 4, weight decay of 0.0005 and momentum of 0.9. In the initial training, YOLO uses 224 × 224 images, and then retune it with 448× 448 images for 10 epochs at a 10−3 learning rate. After the training, the classifier achieves a top-1 accuracy of 76.5% and a top-5 accuracy of 93.3%.
Then the fully connected layers and the last convolution layer is removed for a detector. YOLO adds three 3 × 3 convolutional layers with 1024 filters each followed by a final 1 × 1 convolutional layer with 125 output channels. (5 box predictions each with 25 parameters) YOLO also add a passthrough layer. YOLO trains the network for 160 epochs with a starting learning rate of 10−3 , dividing it by 10 at 60 and 90 epochs. YOLO uses a weight decay of 0.0005 and momentum of 0.9.
Classification
Datasets for object detection have far fewer class categories than those for classification. To expand the classes that YOLO can detect, YOLO proposes a method to mix images from both detection and classification datasets during training. It trains the end-to-end network with the object detection samples while backpropagates the classification loss from the classification samples to train the classifier path. This approach encounters a few challenges:
1
2
3
- How do we merge class labels from different datasets? In particular, object detection datasets and different classification datasets uses different labels.
- Any merged labels may not be mutually exclusive, for example, Norfolk terrier in ImageNet and dog in COCO. Since it is not mutually exclusive, we can not use softmax to compute the probability.
Hierarchical classification
Without going into details, YOLO combines labels in different datasets to form a tree-like structure WordTree. The children form an is-a relationship with its parent like biplane is a plane. But the merged labels are now not mutually exclusive.
YOLO 9000
YOLO9000 extends YOLO to detect objects over 9000 classes using hierarchical classification with a 9418 node WordTree. It combines samples from COCO and the top 9000 classes from the ImageNet. YOLO samples four ImageNet data for every COCO data. It learns to find objects using the detection data in COCO and to classify these objects with ImageNet samples.
During the evaluation, YOLO test images on categories that it knows how to classify but not trained directly to locate them, i.e. categories that do not exist in COCO. YOLO9000 evaluates its result from the ImageNet object detection dataset which has 200 categories. It shares about 44 categories with COCO. Therefore, the dataset contains 156 categories that have never been trained directly on how to locate them. YOLO extracts similar features for related object types. Hence, we can detect those 156 categories by simply from the feature values.
YOLO9000 gets 19.7 mAP overall with 16.0 mAP on those 156 categories. YOLO9000 performs well with new species of animals not found in COCO because their shapes can be generalized easily from their parent classes. However, COCO does not have bounding box labels for any type of clothing so the test struggles with categories like “sunglasses”.
YOLOv3
The official title of YOLO v2 paper seemed if YOLO was a milk-based health drink for kids rather than a object detection algorithm. It was named “YOLO9000: Better, Faster, Stronger”. For it’s time YOLO 9000 was the fastest, and also one of the most accurate algorithm. However, a couple of years down the line and it’s no longer the most accurate with algorithms like RetinaNet, and SSD outperforming it in terms of accuracy. It still, however, was one of the fastest.
But that speed has been traded off for boosts in accuracy in YOLOv3 [4]. While the earlier variant ran on 45 FPS on a Titan X, the current version clocks about 30 FPS. This has to do with the increase in complexity of underlying architecture called Darknet.
Class Prediction
Most classifiers assume output labels are mutually exclusive. It is true if the output are mutually exclusive object classes. Therefore, YOLO applies a softmax function to convert scores into probabilities that sum up to one. YOLOv3 uses multi-label classification. For example, the output labels may be “pedestrian” and “child” which are not non-exclusive. (the sum of output can be greater than 1 now.) YOLOv3 replaces the softmax function with independent logistic classifiers to calculate the likeliness of the input belongs to a specific label. Instead of using mean square error in calculating the classification loss, YOLOv3 uses binary cross-entropy loss for each label. This also reduces the computation complexity by avoiding the softmax function.
Bounding box prediction & cost function calculation
YOLOv3 predicts an objectness score for each bounding box using logistic regression. YOLOv3 changes the way in calculating the cost function. If the bounding box prior (anchor) overlaps a ground truth object more than others, the corresponding objectness score should be 1. For other priors with overlap greater than a predefined threshold (default 0.5), they incur no cost. Each ground truth object is associated with one boundary box prior only. If a bounding box prior is not assigned, it incurs no classification and localization lost, just confidence loss on objectness. We use tx and ty (instead of bx and by) to compute the loss.
1
2
3
4
b_x = sigma(tx) + cx
b_y = sigma(ty) + cy
b_w = p_w * e^(tw)
b_h = p_h * e^(th)
Feature Pyramid Networks (FPN) like Feature Pyramid
YOLOv3 makes 3 predictions per location. Each prediction composes of a boundary box, a objectness and 80 class scores, i.e. N × N × [3 × (4 + 1 + 80) ] predictions.
YOLOv3 makes predictions at 3 different scales (similar to the FPN):
1
2
3
4
5
1) In the last feature map layer.
2) Then it goes back 2 layers back and upsamples it by 2. YOLOv3 then takes a feature map with higher resolution and merge it with the upsampled feature map using element-wise addition. YOLOv3 apply convolutional filters on the merged map to make the second set of predictions.
3) Repeat 2 again so the resulted feature map layer has good high-level structure (semantic) information and good resolution spatial information on object locations.
To determine the priors, YOLOv3 applies k-means cluster. Then it pre-select 9 clusters. For COCO, the width and height of the anchors are (10×13),(16×30),(33×23),(30×61),(62×45),(59× 119),(116 × 90),(156 × 198),(373 × 326). These 9 priors are grouped into 3 different groups according to their scale. Each group is assigned to a specific feature map in detecting objects.
Feature extractor
A new 53-layer Darknet-53 is used to replace the Darknet-19 as the feature extractor. Darknet-53 mainly compose of 3 × 3 and 1× 1 filters with skip connections like the residual network in ResNet. Darknet-53 has less BFLOP (billion floating point operations) than ResNet-152, but achieves the same classification accuracy at 2x faster.
YOLOv3 Performance
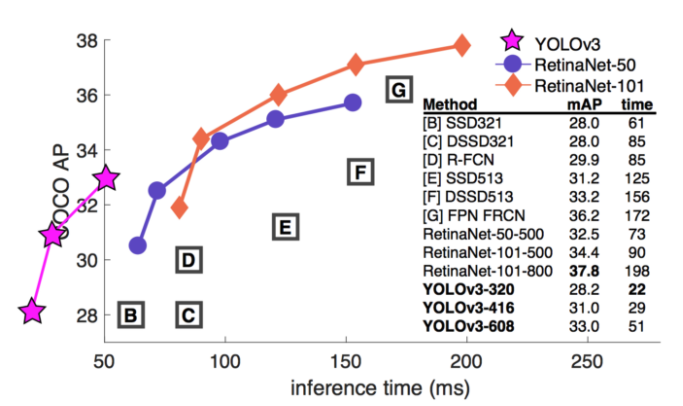
YOLOv3’s COCO AP metric is on par with SSD but 3x faster. But YOLOv3’s AP is still behind RetinaNet. In particular, AP@IoU=.75 drops significantly comparing with RetinaNet which suggests YOLOv3 has higher localization error. YOLOv3 also shows significant improvement in detecting small objects.
YOLOv3 performs very well in the fast detector category when speed is important.
Do we need to keep doing research about CV
On 21st February 2020, Joseph Redmon, a creator of the popular object detection algorithm YOLO (You Only Look Once), tweeted that he had ceased his computer vision research to avoid enabling potential misuse of the tech — citing in particular “military applications and privacy concerns.”
His comment emerged from a Twitter discussion on last Wednesday’s announcement of revised NeurIPS 2020 paper submission guidelines, which now ask authors to add a section on the broader impact of their work “including possible societal consequences — both positive and negative.”
Redmon said he felt certain degree humiliation for ever believing “science was apolitical and research objectively moral and good no matter what the subject is.” He said he’d come to realize that facial recognition technologies have more downside than upside, and that they would not be developed if enough researchers thought about the broader impact of the enormous downside risks.
Ethical discussions around AI are not new and will undoubtedly intensify as the technologies move from labs to the streets. This new attention from a high-profile conference like NeurIPS and Redmon’s recent reveal suggest that experts in particular fields will join the broader ML community and the general public in this ongoing process.
YOLOv4
In fact, no one in the research community expected a YOLOv4 to be released, since Joseph Redmon, the original author, recently announced that he would stop doing computer vision research because of the military and ethical issues.
The main contributor of the YOLOv4 is Alexey Bochkovskiy, who is also know as “AlexeyAB”, the one who created the Windows version of YOLOv2 and YOLOv3. Definitely, he helped a lot of engineers (me included) in implementing YOLO in object detection projects.
The YOLOv4 model outperformed the YOLOv3 model, and showed interesting results.
DarkNet to CSPDarkNet
The main changes between YOLOv3 and YOLOv4 is a new backbone network. The creators of the YOLOv4 appended more layers to increase the accuracy of the YOLOv4 model. Since they added more layers, the number of parameters also increased. This means that the training time is also increased. To overcome this issue, the creators of the YOLOv4 developed a new backbone network by using the CSPNet.
Cross-Stage-Partial-connections (CSP)
CSPNet separates the input feature maps of the DenseBlock into two parts. The first part x0’ bypasses the DenseBlock and becomes part of the input to the next transition layer. The second part x0” will go thought the Dense block as below.
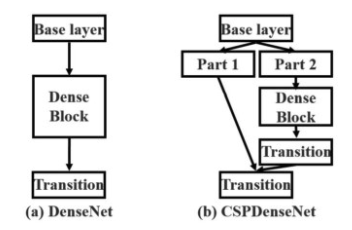
This new design reduces the computational complexity by separating the input into two parts — with only one going through the Dense Block.
CSPDarkNet
YOLOv4 utilizes the CSP connections above with the Darknet-53 below as the backbone in feature extraction.
The CSPDarknet53 model has higher accuracy in object detection compared with ResNet based designs even they have a better classification performance. But the classification accuracy of CSPDarknet53 can be improved with Mish and other techniques discussed later. The final choice for YOLOv4 is therefore CSPDarknet53.
Neck
Object detectors composed of a backbone in feature extraction and a head (the rightmost block below) for object detection. And to detect objects at different scales, a hierarchy structure is produced with the head probing feature maps at different spatial resolutions.
To enrich the information that feeds into the head, neighboring feature maps coming from the bottom-up stream and the top-down stream are added together element-wise or concatenated before feeding into the head. Therefore, the head’s input will contain spatial rich information from the bottom-up stream and the semantic rich information from the top-down stream. This part of the system is called a neck. Let’s get more details in its design.
Feature Pyramid Networks (FPN)
YOLOv3 adapts a similar approach as FPN in making object detection predictions at different scale levels.
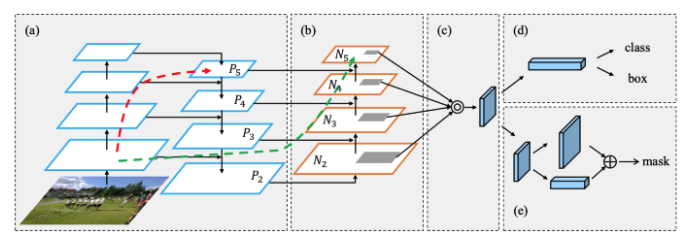
In making predictions for a particular scale, FPN upsamples (2×) the previous top-down stream and add it with the neighboring layer of the bottom-up stream. The result is passed into a 3×3 convolution filter to reduce upsampling artifacts and create the feature maps P4 below for the head.
SPP (spatial pyramid pooling layer)
SPP applies a slightly different strategy in detecting objects of different scales. It replaces the last pooling layer (after the last convolutional layer) with a spatial pyramid pooling layer. The feature maps are spatially divided into m×m bins with m, say, equals 1, 2, and 4 respectively. Then a maximum pool is applied to each bin for each channel. This forms a fixed-length representation that can be further analyzed with FC-layers.
Many CNN-based models containing FC-layers and therefore, accepts input images of specific dimensions only. In contrast, SPP accepts images of different sizes. Nevertheless, there are technologies like fully convolution networks (FCN) that contain no FC-layers and accepts images of different dimensions. This type of design is particularly useful for image segmentation which spatial information is important. Therefore, for YOLO, convert 2-D feature maps into a fixed-size 1-D vector is not necessarily desirable.
YOLO with SPP
In YOLO, the SPP is modified to retain the output spatial dimension. A maximum pool is applied to a sliding kernel of size say, 1×1, 5×5, 9×9, 13×13. The spatial dimension is preserved. The features maps from different kernel sizes are then concatenated together as output.
Path Aggregation Network (PAN)
In early DL, the model design is relatively simple. Each layer takes input from the previous layer. The early layers extract localized texture and pattern information to build up the semantic information needed in the later layers. However, as we progress to the right, localized information that may be needed to fine-tune the prediction may be lost.
In later DL development, the interconnectivity among layers is getting more complex. In DenseNet, it goes to the extreme. Each layer is connected with all previous layers. In FPN, information is combined from neighboring layers in the bottom-up and top-down stream. The flow of information among layers becomes another key decision in the model design.
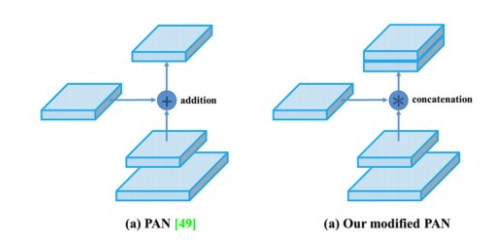
The diagram below is the Path Aggregation Network (PAN) for object detection. A bottom-up path (b) is augmented to make low-layer information easier to propagate to the top. In FPN, the localized spatial information traveled upward in the red arrow. While not clearly demonstrates in the diagram, the red path goes through about 100+ layers. PAN introduced a short-cut path (the green path) which only takes about 10 layers to go to the top N₅ layer. This short-circuit concepts make fine-grain localized information available to top layers.
However, instead of adding neighbor layers together, features maps are concatenated together in YOLOv4.
Spatial Attention Module (SAM)
Attention has widely adopted in DL designs. In SAM, maximum pool and average pool are applied separately to input feature maps to create two sets of feature maps. The results are feed into a convolution layer followed by a sigmoid function to create spatial attention. This spatial attention mask is applied to the input feature to output the refined feature maps.
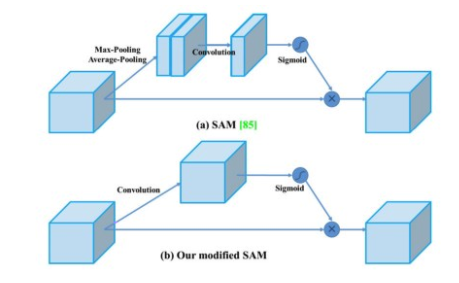
In YOLOv4, a modified SAM is used without applying the maximum and average pooling.
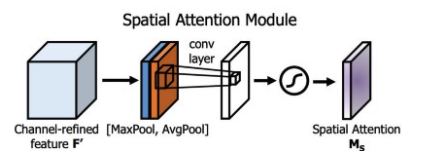
In YOLOv4, the FPN concept is gradually implemented/replaced with the modified SPP, PAN, and PAN.
Bag of Freebies (BoF) for backbone
The BoF features for YOLOv4 backbone include:
1
2
3
- CutMix and Mosaic data augmentation
- DropBlock regularization
- Class label smoothing
CutMix data augmentation
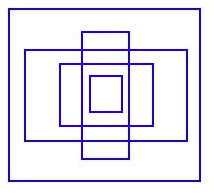
Cutout data augmentation removes a region of an image (see the diagram below). This forces the model not to be overconfident on specific features in making classifications. However, a portion of the image is filled with useless information and this is a waste. In CutMix [7], a portion of an image is cut-and-paste over another image. The ground truth labels are readjusted proportionally to the area of the patches, e.g. 0.6 like a dog and 0.4 like a cat.
Conceptually, CutMix has a broader view of what an object may compose of. The cutout area forces the model to learn object classification with different sets of features. This avoids overconfidence. Since that area is replaced with another image, the amount of information in the image and the training efficient will not be impacted significantly also.
Mosaic data augmentation
Mosaic is a data augmentation method that combines 4 training images into one for training (instead of 2 in CutMix). This enhances the detection of objects outside their normal context. In addition, each mini-batch contains a large variant of image (4×) and therefore, reduces the need for large mini-batch sizes in estimating the mean and the variance.
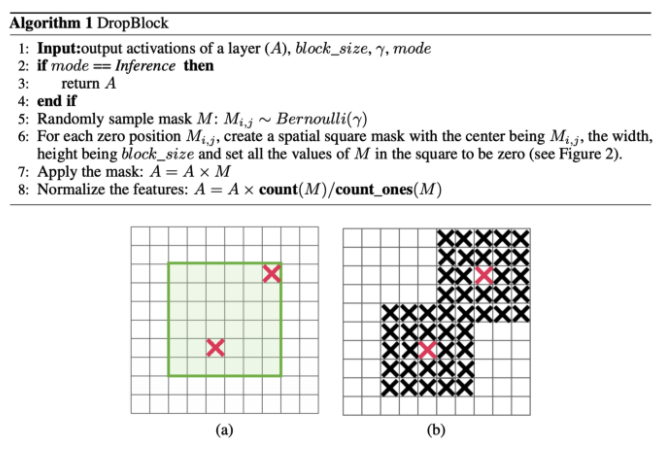
DropBlock regularization
In Fully-connected layers, we can apply dropoff to force the model to learn from a variety of features instead of being too confident on a few. However, this may not work for convolution layers. Neighboring positions are highly correlated. So even some of the pixels are dropped (the middle diagram below), the spatial information remains detectable. DropBlock regularization builds on a similar concept that works on convolution layers.
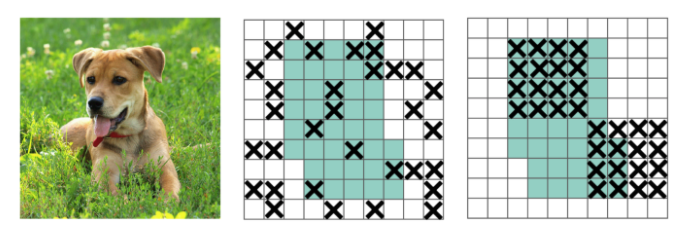
Instead of dropping individual pixels, a block of block_size × block_size of pixels is dropped.
Class label smoothing
Whenever you feel absolutely right, you may be plainly wrong. A 100% confidence in a prediction may reveal that the model is memorizing the data instead of learning. Label smoothing adjusts the target upper bound of the prediction to a lower value say 0.9. And it will use this value instead of 1.0 in calculating the loss. This concept mitigates overfitting.
YOLOv5
Apr 23rd, 2020 — YOLOv4 was released.
And on June 10th 2020, YOLOv5 was also released.
Glenn Jocher the founder and CEO of Ultralytics released its open source implementation of YOLOv5 repo on GitHub [5], which supposedly said to be the state of the art among all known YOLO implementations according to the Ultralytics GitHub page.
Based on their results is shows how well it outperformed EfficientDet which is Googles open source object detection framework, but what I find strange is that while they do not explicitly show their comparison with YOLOv4, YOLOv5 is said to be able to achieve fast detection at 140FPS running on a Tesla P100 in comparison to YOLOv4 which bench-marked at a measly 50 FPS stated on an article.
Furthermore, they mentioned that “YOLOv5 is small at only 27 Megabytes”. What, that is ridiculously small compared to the 244 megabytes of YOLOv4 with darknet architecture…Whaaat.. That’s nearly 90 percent small than YOLOv4.
Is YOLOv5 actually here
Redmon had created 3 iterations of YOLO in partnership with Ali Faradi.
Now later this year YOLOv4 appeared in April 2020 but by none of the original authors but rather by Bochkovskiy et. al. The paper was published and peer reviewed, GitHub code uploaded to the AlexeyAB/darknet repo and everything seemed fine, the technological upgrade was great and well received in the computer vision community. So does this mean that if Bochkovskiy et. al. did it, then anyone else can take the YOLO framework, make some improvements and increment the version number? Well that’s exactly what happened.
I strongly recommend you to read this article, and rethink about YOLOv5 model. Is it actually here in 2020?
References
[1] Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi. You Only Look Once: Unified, Real-Time Object Detection
[2] Jonathan Hui. Real-time Object Detection with YOLO, YOLOv2 and now YOLOv3
[3] Joseph Redmon, Ali Farhadi. YOLO9000: Better, Faster, Stronger
[4] Joseph Redmon, Ali Farhadi. YOLOv3: An Incremental Improvement
[5] Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao. YOLOv4: Optimal Speed and Accuracy of Object Detection
[6] Ultralytics. YOLOv5 GitHub Repository
[7] Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, Youngjoon Yoo. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features